import numpy as np
from moraine.utils_ import is_cuda_available
if is_cuda_available():
import cupy as cp
from matplotlib import pyplot as pltPoint Cloud data utility
Two kind of indices are supported. One is called grid index or gix. gix is expressed as sorted int32 array with shape (n_points,2). gix[:,0] is their azimuth indices and gix[:,1] is the range indices. gix is first sorted in azimuth indices and then sorted in range indices. Here is an example:
array([[0, 2],
[1, 0],
[1, 3],
[3, 2]], dtype=int32)The advantage of gix is that it is directly connected to the original raster indices. While the disadvantage is it does not maintain locality, i.e., two points that are geographical close to each other may not be close to each other in the storage which makes data query (e.g., find all points that within a bounding box) inefficient.
To solve that, another kind indices called hillbert index or hix is introduced. hix is expressed as sorted int64 array with shape (n_point,). Note that hix is calculated by gix.
Warning
hix of two point cloud datasets calculated with different grids are not compatitable.
Warning
Please see pc_hix for how to generate hix.
pc_hix
pc_hix (gix, shape:tuple)
Compute the hillbert index for point cloud data.
| Type | Details | |
|---|---|---|
| gix | grid index | |
| shape | tuple | (nlines, width) |
| Returns | ndarray |
usage:
gix = np.random.choice(np.arange(100*100,dtype=np.int32),size=1000,replace=False)
gix.sort()
gix = np.stack(np.unravel_index(gix,shape=(100,100)),axis=-1).astype(np.int32)
hix = pc_hix(gix, (100,100))plt.scatter(gix[:,1], gix[:,0], c=hix)
plt.colorbar()
plt.show()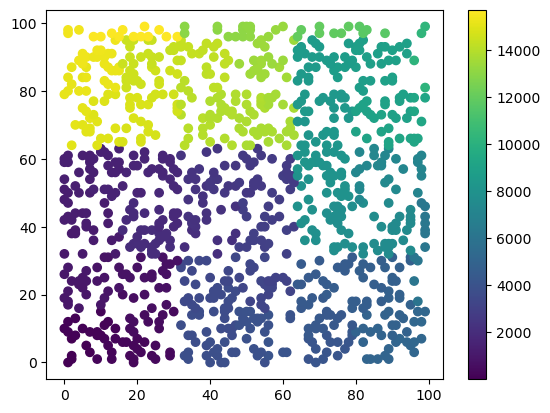
Hillbert index have a very useful locality property:
- Points with hillbert indexes close to an index will be geometrically close to the point corresponding to that index.
This enable fast data query of billions of points. See rtree for data query.
pc_gix
pc_gix (hix, shape:tuple)
convert hillbert index to grid index.
| Type | Details | |
|---|---|---|
| hix | hillbert index | |
| shape | tuple | (nlines, width) |
| Returns | ndarray |
gix = np.random.choice(np.arange(100*100,dtype=np.int32),size=1000,replace=False)
gix.sort()
gix = np.stack(np.unravel_index(gix,shape=(100,100)),axis=-1).astype(np.int32)
hix = pc_hix(gix, (100,100))
gix_ = pc_gix(hix, (100,100))
np.testing.assert_array_equal(gix,gix_)pc_sort
pc_sort (idx:numpy.ndarray, shape:tuple=None)
Get the indices that sort the input.
| Type | Default | Details | |
|---|---|---|---|
| idx | ndarray | unsorted gix (2D) or hix(1D) |
|
| shape | tuple | None | (nline, width), faster if provided for grid index input |
| Returns | ndarray | indices that sort input |
Warning
gix = np.stack(([0,1,5,3,4,3],[3,5,2,4,6,8]),axis=-1)
key = pc_sort(gix,shape=(6,9))
np.testing.assert_equal(gix[key],np.stack(([0,1,3,3,4,5],[3,5,4,8,6,2]),axis=-1))hix = np.array([0,1,5,4,3])
key = pc_sort(hix)
np.testing.assert_equal(hix[key],np.array([0,1,3,4,5]))pc2ras
pc2ras (idx:numpy.ndarray, pc_data:numpy.ndarray, shape:tuple)
convert point cloud data to original raster, filled with nan
| Type | Details | |
|---|---|---|
| idx | ndarray | gix or hix array |
| pc_data | ndarray | data, 1D or more |
| shape | tuple | image shape |
# usage:
a = np.arange(1000*50,dtype=np.float32).reshape(1000,50)
gix = np.random.choice(np.arange(100*50,dtype=np.int32),size=1000,replace=False)
gix.sort()
gix = np.stack(np.unravel_index(gix,shape=(100,50)),axis=-1).astype(np.int32)
a_raster = pc2ras(gix,a,shape=(100,50))
np.testing.assert_array_equal(a_raster[gix[:,0],gix[:,1]],a)
# or:
hix = pc_hix(gix,shape=(100,50))
key = pc_sort(hix)
a_raster_ = pc2ras(hix[key],a[key],shape=(100,50))
np.testing.assert_array_equal(a_raster,a_raster_)ras2pc
ras2pc (ras, gix)
pc_union
pc_union (idx1:numpy.ndarray, idx2:numpy.ndarray, shape:tuple=None)
Get the union of two point cloud dataset. For points at their intersection, prefer idx1 rather than idx2
| Type | Default | Details | |
|---|---|---|---|
| idx1 | ndarray | int array, grid index or hillbert index of the first point cloud | |
| idx2 | ndarray | int array, grid index or hillbert index of the second point cloud | |
| shape | tuple | None | image shape, faster if provided for grid index input |
| Returns | tuple | the union index idx; index of the point in output union index that originally in the first point cloud inv_iidx;index of the point in output union index that only exist in the second point cloud inv_iidx2;index of the point in the second input index that are not in the first input point cloud |
Usage:
if is_cuda_available():
ras = cp.array([[4,3,8,3],
[4,7,2,6],
[9,0,3,7],
[1,4,2,6]])
gix1 = cp.stack((cp.array([0,0,1,1,2,3]),
cp.array([2,3,0,3,1,2])),axis=-1,).astype(cp.int32)
gix2 = cp.stack((cp.array([0,0,1,2,2,3]),
cp.array([0,3,1,1,3,1])),axis=-1,).astype(cp.int32)
pc_data1 = cp.array([3,2,5,4,32,2])
pc_data2 = cp.array([3,5,6,2,1,4])
gix, inv_iidx1, inv_iidx2, iidx2 = pc_union(gix1,gix2, shape=(4,4))With all the returns in pc_union, it is very easy to construct the union data:
if is_cuda_available():
pc_data = cp.empty((gix.shape[0],*pc_data1.shape[1:]),dtype=pc_data1.dtype)
pc_data[inv_iidx1] = pc_data1
pc_data[inv_iidx2] = pc_data2[iidx2]
np.testing.assert_equal(cp.asnumpy(pc_data),np.array([3,3,2,5,6,4,32,1,4,2]))
np.testing.assert_equal(cp.asnumpy(ras[gix[:,0],gix[:,1]]),np.array([4,8,3,4,7,6,0,7,4,2]))For data with hix:
if is_cuda_available():
hix1 = cp.array([2,4,6,8,10],dtype=np.int64)
hix2 = cp.array([1,2,3,6,9],dtype=np.int64)
pc_data1 = cp.array([3,2,5,4,32])
pc_data2 = cp.array([3,5,6,2,1])
hix, inv_iidx1, inv_iidx2, iidx2 = pc_union(hix1,hix2)
pc_data = cp.empty((hix.shape[-1],*pc_data1.shape[1:]),dtype=pc_data1.dtype)
pc_data[inv_iidx1] = pc_data1
pc_data[inv_iidx2] = pc_data2[iidx2]
np.testing.assert_equal(cp.asnumpy(pc_data),np.array([3,3,6,2,5,4,1,32]))pc_intersect
pc_intersect (idx1:numpy.ndarray, idx2:numpy.ndarray, shape:tuple=None)
Get the intersection of two point cloud dataset.
| Type | Default | Details | |
|---|---|---|---|
| idx1 | ndarray | int array, grid index or hillbert index of the first point cloud | |
| idx2 | ndarray | int array, grid index or hillbert index of the second point cloud | |
| shape | tuple | None | image shape, faster if provided for grid index input |
| Returns | tuple |
if is_cuda_available():
ras = cp.array([[4,3,8,3],
[4,7,2,6],
[9,0,3,7],
[1,4,2,6]])
gix1 = cp.stack((cp.array([0,0,1,1,2,3]),
cp.array([2,3,0,3,1,2])),axis=-1,).astype(cp.int32)
gix2 = cp.stack((cp.array([0,0,1,2,2,3]),
cp.array([0,3,1,1,3,1])),axis=-1,).astype(cp.int32)
pc_data1 = cp.array([3,2,5,4,32,2])
pc_data2 = cp.array([3,5,6,2,1,4])
gix, iidx1, iidx2 = pc_intersect(gix1,gix2,shape=(4,4))
pc_data_int1 = pc_data1[iidx1]
pc_data_int2 = pc_data2[iidx2]
np.testing.assert_equal(cp.asnumpy(gix),np.array([[0,3],
[2,1]]))
np.testing.assert_equal(cp.asnumpy(ras[(gix[:,0],gix[:,1])]),np.array([3,0]))
np.testing.assert_equal(cp.asnumpy(pc_data_int1),np.array([2,32]))
np.testing.assert_equal(cp.asnumpy(pc_data_int2),np.array([5,2]))if is_cuda_available():
hix1 = cp.array([2,3,4,7,9,14], dtype=np.int64)
hix2 = cp.array([0,3,5,9,11,13],dtype=np.int64)
pc_data1 = cp.array([3,2,5,4,32,2])
pc_data2 = cp.array([3,5,6,2,1,4])
hix, iidx1, iidx2 = pc_intersect(hix1,hix2)
pc_data_int1 = pc_data1[iidx1]
pc_data_int2 = pc_data2[iidx2]
np.testing.assert_equal(cp.asnumpy(hix),np.array([3,9]))
np.testing.assert_equal(cp.asnumpy(pc_data_int1),np.array([2,32]))
np.testing.assert_equal(cp.asnumpy(pc_data_int2),np.array([5,2]))pc_diff
pc_diff (idx1:numpy.ndarray, idx2:numpy.ndarray, shape:tuple=None)
Get the point cloud in idx1 that are not in idx2.
| Type | Default | Details | |
|---|---|---|---|
| idx1 | ndarray | int array, grid index or hillbert index of the first point cloud | |
| idx2 | ndarray | int array, grid index or hillbert index of the second point cloud | |
| shape | tuple | None | image shape, faster if provided for grid index input |
| Returns | tuple | the diff index idx,index of the point in first point cloud index that do not exist in the second point cloud, |
if is_cuda_available():
gix1 = cp.stack((cp.array([0,0,1,1,2,3]),
cp.array([2,3,0,3,1,2])),axis=-1,).astype(cp.int32)
gix2 = cp.stack((cp.array([0,0,1,2,2,3]),
cp.array([0,3,1,1,3,1])),axis=-1,).astype(cp.int32)
gix, iidx1 = pc_diff(gix1,gix2, shape=(4,4))
pc_data_diff = pc_data1[iidx1]
np.testing.assert_equal(cp.asnumpy(gix),np.stack(([0,1,1,3],[2,0,3,2]),axis=-1))
np.testing.assert_equal(cp.asnumpy(iidx1),np.array([0,2,3,5]))if is_cuda_available():
hix1 = cp.array([2,3,4,7,9,14], dtype=np.int64)
hix2 = cp.array([0,3,5,9,11,13],dtype=np.int64)
hix, iidx1 = pc_diff(hix1,hix2)
pc_data_diff = pc_data1[iidx1]
np.testing.assert_equal(cp.asnumpy(hix),np.array([2,4,7,14]))
np.testing.assert_equal(cp.asnumpy(iidx1),np.array([0,2,3,5]))